分发策略
Karmada 提供了 PropagationPolicy 和 ClusterPropagationPolicy 两种 API 用于资源分发。关于这两种 API 的区别,可参考 此处。
本指南通过解释 API 规范中的每个字段来描述 PropagationPolicy 的配置选项。ClusterPropagationPolicy 与其共享相同的 spec 结构,因此示例对两者均适用。
ResourceSelectors(资源选择器)
resourceSelectors 字段指定应分发哪些资源。必须至少定义一个选择器。
ResourceSelector 通过 API 版本和 Kind 匹配资源,并可选择性地通过名称、标签和命名空间进一步筛选。如果未设置 name 或 labelSelector,它将匹配有效命名空间中(默认为策略的命名空间)给定 APIVersion/Kind 的所有资源。
匹配策略命名空间中的所有资源
如果省略 name 和 labelSelector,选择器将匹配有效命名空间(默认为策略命名空间)中指定 APIVersion/Kind 的所有资源:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: all-deployments
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinity:
clusterNames:
- member1
- member2
这将匹配策略命名空间中的所有 Deployment。
对于 ClusterPropagationPolicy,相同的选择器将匹配所有命名空间中的 Deployment。
按名称匹配
按名称匹配特定资源:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
这仅匹配策略命名空间中名为 nginx 的 Deployment。
按标签匹配
通过标签选择器匹配资源:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: app-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
labelSelector:
matchLabels:
app: nginx
placement:
clusterAffinity:
clusterNames:
- member1
这将匹配策略命名空间中带有标签 app=nginx 的 Deployment。
PropagateDeps(分发依赖)
propagateDeps 字段控制是否应自动分发依赖资源。
启用时,被分发工作负载引用的资源(例如,Deployment 引用的 ConfigMap 和 Secret)将自动分发,无需在 resourceSelectors 中列出它们。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
namespace: default
name: nginx
propagateDeps: true
placement:
clusterAffinity:
clusterNames:
- member1
这会将 nginx Deployment 及其引用的依赖项分发到 member1。
Placement(分发位置)
placement 字段指定资源应如何分发到各个集群。它包括集群亲和性、扩散约束和副本调度策略。
Cluster Affinity(集群亲和性)
.spec.placement.clusterAffinity 字段表示调度限制,用于限制可选择哪些集群。如果未��指定,任何集群都可以成为调度候选集群。
ClusterAffinity 支持四种过滤机制:
- LabelSelector(标签选择器):按标签过滤集群
- FieldSelector(字段选择器):按字段(provider、region、zone)过滤集群
- ClusterNames(集群名称):显式列出集群名称
- ExcludeClusters(排除集群):显式排除集群名称
当指定多个过滤机制时,它们以逻辑 AND 组合,这意味着集群必须匹配所有指定条件才能被选中。
clusterAffinity 定义了集群的候选集——它指定哪些集群有资格被选择,但不保证它们都会被选中。调度器会根据各种因素(如调度策略、集群健康状况和资源可用性)从此候选集中进行选择。要严格控制选择多少个集群,请将 spreadConstraints 与 clusterAffinity 结合使用。
例如,如果在 clusterNames 中指定了 10 个集群,但希望确保仅选择 2 个,可将其与 spreadConstraints 结合,使用 spreadByField: cluster 并设置 maxGroups: 2, minGroups: 2。
LabelSelector(标签选择器)
LabelSelector 是按标签选择成员集群的过滤器。它使用 *metav1.LabelSelector 类型。如果它非 nil 且非空,它将过滤候选集以仅包含匹配此过滤器的集群。
PropagationPolicy 可按如下方式配置:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: test-propagation
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinity:
labelSelector:
matchLabels:
location: us
这将创建标记为 location=us 的集群候选集。
PropagationPolicy 也可按如下方式配置:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: test-propagation
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinity:
labelSelector:
matchExpressions:
- key: location
operator: In
values:
- us
这使用基于集合的选择器过滤候选集,仅包含其 location 标签在 us 中的集群。
有关 matchLabels 和 matchExpressions 的描述,您可以参考支持基于集合的需求的资源。
FieldSelector(字段选择器)
FieldSelector 是按字段选择成员集群的过滤器。如果它非 nil 且非空,它将过滤候选集以仅包含匹配此过滤器的集群。
PropagationPolicy 可按如下方式配置:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinity:
fieldSelector:
matchExpressions:
- key: provider
operator: In
values:
- aws
- key: region
operator: NotIn
values:
- us-west-1
这定义了来自 provider aws 的集群候选集,同时排除 region us-west-1 中的集群。
如果在 fieldSelector 中指定了多个 matchExpressions,集群必须匹配所有 matchExpressions。
matchExpressions 中的 key 现在支持三个值:provider、region 和 zone,它们分别对应 Cluster 对象的 .spec.provider、.spec.region 和 .spec.zone 字段。
matchExpressions 中的 operator 现在支持 In 和 NotIn。
ClusterNames(集群名称)
用户可以设置 ClusterNames 字段来指定选定的集群。
PropagationPolicy 可按如下方式配置:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinity:
clusterNames:
- member1
- member2
这将候选集限制为 member1 和 member2。
ExcludeClusters(排除集群)
显式排除集群被选中:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinity:
exclude:
- member1
- member3
这将从候选集中排除 member1 和 member3。
ClusterAffinities(多个集群组)
clusterAffinities 字段允许定义多个具有回退行为的集群组。clusterAffinity 定义一组选择条件,这些条件一起应用以产生单个候选集群集。clusterAffinities 定义多个有序的条件集(组),这些条件集按顺序评估:调度器尝试第一组,仅当前一组无法满足调度时才回退到下一组。
clusterAffinities 不能与 clusterAffinity 共存。
工作原理
调度器按顺序评估亲和性组:
- 尝试使用第一组进行调度
- 如果第一组不满足调度限制,尝试下一组
- 一个集群可以属于多个组
- 如果没有组满足限制,调度失败
ClusterAffinityTerm
clusterAffinities 中的每个组由一个 ClusterAffinityTerm 定义,包含以下内容:
affinityName:集群组的可读名称- 内联
ClusterAffinity字段,如labelSelector、fieldSelector、clusterNames和exclude:定义该 term 的主集群组 overflowAffinities(可选):附加的有序集群组,仅在同一 term 中的主集群组无法容纳调度时才会被使用
通过 overflowAffinities,可以实现溢出调度场景,例如优先调度到 IDC 集群,当 IDC 资源不足时溢出到云端集群。
由于溢出调度需要感知成员集群的可用资源,目前不支持副本复制模式和静态权重分配与溢出调度组合使用。
overflowAffinities 工作原理
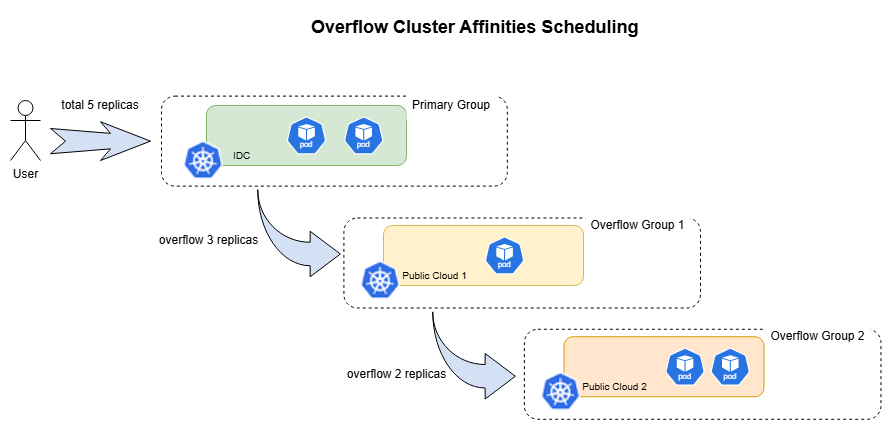
调度器按顺序评估主集群组和溢出集群组:
- 尽可能将副本分配到主集群组。
- 如果主集群组无法容纳所有副本,则尝试将剩余副本分配到溢出集群组。
- 对于每个溢出组,分配的副本数为剩余未分配副本数与该组总可用容量中的较小值。
- 在每个组内,副本根据
placement.replicaScheduling策略分配到各集群。 - 一旦所有副本都能被分配,调度成功。如果评估完所有组后仍有副本未分配, 则此 ClusterAffinityTerm 调度失败,调度器将继续评估 clusterAffinities 中的下一个 ClusterAffinityTerm(如有)。
用例 1:本地集群作为主集群,云集群作为备份
本地数据中心的私有集群可以作为主组,集群提供商提供的托管集群可以作为次要组。调度器会优先调度到主组,仅当主组缺乏资源时才考虑第二组。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: test-propagation
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinities:
- affinityName: local-clusters
clusterNames:
- local-member1
- local-member2
- affinityName: cloud-clusters
clusterNames:
- public-cloud-member1
- public-cloud-member2
这优先选择本地集群,如果它们无法满足调度,则回退到云组。
用例 2:灾难恢复(主集群和备份集群)
集群被组织为主组和备份组。工作负载首先调度到主集群,如果主集群失败则迁移到备份集群。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: test-propagation
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinities:
- affinityName: primary-clusters
clusterNames:
- member1
- member2
- affinityName: backup-clusters
clusterNames:
- member3
- member4
这首先尝试主集群,如果主集群失败,则将工作负载移动到备份组。
用例 3:从 IDC GPU 集群溢出到云端 GPU 集群
IDC GPU 集群可以作为运行 GPU 推理工作负载的主集群组,而云端 GPU 集群可以作为处理额外峰值流量的溢出集群组。调度器会优先将副本填充到 IDC 集群中,仅当 IDC 集群无法容纳所有副本时,才会将剩余副本溢出到云端集群。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: gpu-inference-overflow
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinities:
- affinityName: idc-gpu
clusterNames:
- idc-gpu-cluster1
overflowAffinities:
- affinityName: cloud-gpu
clusterNames:
- cloud-gpu-cluster1
- cloud-gpu-cluster2
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Weighted
weightPreference:
dynamicWeight: AvailableReplicas
这会优先使用 IDC GPU 集群;仅当 IDC 集群无法容纳所有副本时,才会溢出到云端 GPU 集群。当流量下降时,副本会优先从云端 GPU 集群回收,从而保持 GPU 使用的成本效益。
ClusterTolerations(集群容忍)
.spec.placement.clusterTolerations 字段表示集群容忍。与 Kubernetes 类似,容忍与集群上的污点配合使用。
在集群上设置一个或多个污点后,除非策略明确容忍这些污点,否则工作负载无法调度到该集群。Karmada 目前支持具有 NoSchedule 和 NoExecute 效果的污点。
设置集群污点
使用 karmadactl taint 为集群添加污点:
# 使用键 'dedicated'、值 'special-user' 和效果 'NoSchedule' 更新集群 'foo' 的污点
# 如果具有该键和效果的污点已存在,则其值将被替换为指定的值
karmadactl taint clusters foo dedicated=special-user:NoSchedule
容忍集群污点
要调度到被污染的集群,在策略中声明容忍:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterTolerations:
- key: dedicated
value: special-user
effect: NoSchedule
这允许调度到被污染为 dedicated=special-user:NoSchedule 的集群。
NoExecute 效果也用于多集群故障转移。
SpreadConstraints(扩散约束)
.spec.placement.spreadConstraints 字段控制如何根据拓扑域(集群、区域、地带或提供商)将资源分散到集群。
扩散约束的工作原理
扩散约束根据指定字段将集群划分为组,并对选择多少个组施加约束:
- SpreadByField:按内置字段对集群分组
cluster(已支持)region(已支持)zone(尚未实现)provider(尚未实现)
- SpreadByLabel:按自定义标签对集群分组
- MaxGroups:要选择的最大组数
- MinGroups:要选择的最小组数(默认为 1)
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
replicaScheduling:
replicaSchedulingType: Duplicated
spreadConstraints:
- spreadByField: region
maxGroups: 2
minGroups: 2
- spreadByField: cluster
maxGroups: 2
minGroups: 2
这将工作负载分散到恰好两个区域,每个区域一个集群(总共两个集群)。
如果副本分割偏好是 StaticWeightList,则不应用扩散约束。
如果使用 SpreadByField,您还必须指定集群级别的扩散约束。例如,当使用 SpreadByFieldRegion 指定区域组时,您还必须使用 SpreadByFieldCluster 指定要选择多少个集群。
ReplicaScheduling(副本调度)
.spec.placement.replicaScheduling 字段定义在分发具有副本规范的资源(例如 Deployment、StatefulSet 或自定义 CRD)时应如何分配副本。
有两种副本调度类型:
- Duplicated(复制):每个集群接收来自资源规范的完整副本数
- Divided(分割):总副本根据
ReplicaDivisionPreference在选定的集群之间分割
Duplicated 模式
所有选定的集群接收相同数量的副本:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaSchedulingType: Duplicated
这创建了 member1 和 member2 的候选集,并将完整的副本数发送到选定的集群。要确切确保选择多少个集群,请使用 spreadConstraints(参见 SpreadConstraints 部分)。
Divided 模式
总副本在选定的集群之间分割。分割策略由 ReplicaDivisionPreference 确定:
Aggregated(聚合)分割
将副本分割到尽可能少的集群中,同时尊重它们的可用资源。注意:该分割方法不会响应 spreadConstraints 配置因为它旨在最小化所使用的集群数量。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Aggregated
这将副本分割到来自候选集(member1 和 member2)的尽可能少的集群中。
Weighted(加权)分割
按权重分割副本。支持两种权重方法:
StaticWeightList(静态权重列表):显式为集群分配权重
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 2
这按静态权重的比例分配副本。对于 3 个副本:member1 获得 1 个副本(权重 1),member2 获得 2 个副本(权重 2)。
如果您需要精确控制为加权分配选择多少个集群,请将 spreadConstraints 与权重偏好结合:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
spreadConstraints:
- spreadByField: cluster
maxGroups: 2
minGroups: 2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 2
这通过 spreadConstraints 确保恰好选择 2 个集群,并按指定的权重(1:2 比例)在它们之间分配副本。
DynamicWeight(动态权重):根据可用资源生成权重
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
dynamicWeight: AvailableReplicas
这根据可用容量计算权重,因此副本按每个集群可以容纳的数量成比例地分割。
使用 AvailableReplicas,权重基于每个集群可以容纳多少副本来计算:
- 如果集群 A 可以容纳 6 个副本,B 可以容纳 12 个,C 可以容纳 18 个
- 权重变为 A:B:C = 6:12:18 (1:2:3)
- 对于 12 个总副本,分配为 A:2, B:4, C:6
如果 ReplicaDivisionPreference 设置为 Weighted 而没有 WeightPreference,则所有集群权重相等。
WorkloadAffinity(工作负载亲和性)
.spec.placement.workloadAffinity 字段启用工作负载间的亲和性和反亲和性调度策略。这允许您控制工作负载是应该在相同集群上共同调度(亲和性)还是分散到不同集群(反亲和性)。
这对以下场景特别有用:
高可用性:确保重复工作负载在不同集群上运行,避免单点故障共同调度:将相关工作负载调度到同一集群以最小化延迟资源隔离:分离不应共享集群资源的工作负载
工作负载亲和性的工作原理
工作负载亲和性使用资源模板上的标签来定义亲和性组。具有相同标签键值的工作负载属于同一组:
亲和性组通过标签键值对标识(例如app.group=frontend)亲和性组是命名空间范围的:不同命名空间中具有相同标签的工作负载不被视为同一组的一部分- 调度器维护亲和性组的内存索引,以便在调度期间进行高效查找
Affinity(亲和性-共同调度)
亲和性规则确保工作负载调度到同一亲和性组中其他工作负载已存在的集群。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: training-job-affinity
namespace: default
spec:
resourceSelectors:
- apiVersion: batch/v1
kind: Job
labelSelector:
matchLabels:
workload.type: training
placement:
clusterAffinity:
clusterNames:
- member1
- member2
- member3
workloadAffinity:
affinity:
groupByLabelKey: app.group
---
apiVersion: batch/v1
kind: Job
metadata:
name: training-job-1
namespace: default
labels:
app.group: ml-training
workload.type: training
spec:
template:
spec:
containers:
- name: trainer
image: training:latest
---
apiVersion: batch/v1
kind: Job
metadata:
name: training-job-2
namespace: default
labels:
app.group: ml-training
workload.type: training
spec:
template:
spec:
containers:
- name: trainer
image: training:latest
两个训练任务都有标签 app.group=ml-training,因此它们属于同一亲和性组。调度器会将 training-job-2 调度到 training-job-1 运行的同一集群。
对于亲和性组中的第一个工作负载(当不存在具有匹配标签的其他工作负载时),调度器不会阻止调度。这允许创建新的工作负载组而不会遇到调度死锁。
Anti-affinity(反亲和性-分离)
反亲和性规则确保工作负载调度到同一反亲和性组中不存在其他工作负载的集群。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: flink-anti-affinity
namespace: default
spec:
resourceSelectors:
- apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
labelSelector:
matchLabels:
ha.enabled: "true"
placement:
clusterAffinity:
clusterNames:
- member1
- member2
- member3
workloadAffinity:
antiAffinity:
groupByLabelKey: pipeline.id
---
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: flink-pipeline-primary
namespace: default
labels:
pipeline.id: payment-processing
ha.enabled: "true"
spec:
image: flink:1.17
flinkVersion: v1_17
jobManager:
replicas: 1
---
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: flink-pipeline-backup
namespace: default
labels:
pipeline.id: payment-processing
ha.enabled: "true"
spec:
image: flink:1.17
flinkVersion: v1_17
jobManager:
replicas: 1
两个 FlinkDeployment 都有标签 pipeline.id=payment-processing,因此它们属于同一反亲和性组。调度器将确保它们在不同的集群上运行以提供高可用性。
组合亲和性和反亲和性
您可以在同一策略中指定亲和性和反亲和性规则。在调度期间两个规则都必须满足:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: combined-affinity
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinity:
clusterNames:
- member1
- member2
- member3
workloadAffinity:
affinity:
groupByLabelKey: app.stack
antiAffinity:
groupByLabelKey: app.instance
这确保:
- 具有相同
app.stack标签值的工作负载在同一集群上共同调度 - 具有相同
app.instance标签值的工作负载在不同集群之间分离
工作负载亲和性在调度期间作为硬性要求进行评估。如果无法满足亲和性或反亲和性规则,调度将失败。这确保亲和性保证得到严格执行。
对软亲和性偏好的支持(例如 PreferredDuringScheduling)可能会在未来版本中添加,如果有足够的使用场景。
Priority(优先级)
.spec.priority 字段确定当多个策略匹配一个资源时应用哪个策略。值越高优先级越高。
- 默认优先级:0
- 当优先级相等时,使用隐式优先级(基于 ResourceSelector 特异性)
- 当两者都相等时,字母顺序决定选择
显式优先级
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: high-priority-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
priority: 10
placement:
clusterAffinity:
clusterNames:
- member1
---
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: low-priority-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
priority: 5
placement:
clusterAffinity:
clusterNames:
- member2
nginx deployment 将被分发到 member1(更高优先级)。
隐式优先级
当显式优先级相等时,基于 ResourceSelector 特异性的隐式优先级适用:
- 名称匹配(最高)
- 标签选择器匹配
- APIVersion + Kind 匹配(最低)
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: name-match
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
---
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: label-match
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
labelSelector:
matchLabels:
app: nginx
placement:
clusterAffinity:
clusterNames:
- member2
nginx deployment 将被分发到 member1(名称匹配具有比标签匹配更高的隐式优先级)。
Preemption(抢占)
.spec.preemption 字段控制此策略是否可以抢占由较低优先级策略声明的资源。
- Always:可以抢占由较低优先级策略声明的资源
- Never(默认):不能抢占资源
抢占规则
Karmada 根据策略类型和优先级遵循特定的抢占规则:
-
PropagationPolicy (PP) 抢占另一个 PropagationPolicy:具有
preemption: Always的高优先级 PP 可以抢占低优先级 PP。 -
PropagationPolicy 抢占 ClusterPropagationPolicy (CPP):具有
preemption: Always的 PP 可以始终抢占任何 CPP,无论优先级如何。这是因为命名空间范围的策略 (PP) 比集群范围的策略 (CPP) 具有更高的优先级。 -
ClusterPropagationPolicy 抢占另一个 ClusterPropagationPolicy:具有
preemption: Always的高优先级 CPP 可以抢占低优先级 CPP。 -
ClusterPropagationPolicy 不能抢占 PropagationPolicy:CPP 永远不能抢占 PP,即使 CPP 具有更高的优先级。这确保命名空间范围的策略始终优先。
总结:整体抢占层次结构为:高优先级 PP > 低优先级 PP > 高优先级 CPP > 低优先级 CPP
示例
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: high-priority-policy
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
priority: 10
preemption: Always
placement:
clusterAffinity:
clusterNames:
- member1
优先级为 10 的 PropagationPolicy 可以抢占:
- 同一命名空间中优先级 < 10 的任何其他 PropagationPolicy
- 声明相同资源的任何 ClusterPropagationPolicy(无论优先级如何)
DependentOverrides(依赖覆盖)
.spec.dependentOverrides 字段指定在此分发策略生效之前必须存在哪些覆盖策略。
这在同时创建策略和资源时很有用,确保在分发开始之前覆盖策略已就位。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
dependentOverrides:
- my-override-policy
placement:
clusterAffinity:
clusterNames:
- member1
这会延迟分发,直到 my-override-policy 覆盖存在。
SchedulerName(调度器名称)
.spec.schedulerName 字段指定哪个调度器应处理此策略。如果未指定,使用默认调度器。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: custom-scheduler-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
schedulerName: custom-scheduler
placement:
clusterAffinity:
clusterNames:
- member1
此策略由名为 custom-scheduler 的自定义调度器调度。
Failover(故障转移)
.spec.failover 字段定义当集群失败时应如何迁移应用程序。如果未指定,则禁用故障转移。
有关详细配置,请参阅故障转移分析。
ConflictResolution(冲突解决)
.spec.conflictResolution 字段指定如何处理目标集群中已存在的资源。
- Abort(默认):停止分发以避免意外覆盖
- Overwrite:覆盖现有资源
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
conflictResolution: Overwrite
placement:
clusterAffinity:
clusterNames:
- member1
这会覆盖 member1 中任何现有的 nginx Deployment。
ActivationPreference(激活偏好)
.spec.activationPreference 字段控制资源模板如何响应分发策略的变更。
- 空值(默认):资源模板立即响应策略变更,即任何策略变更都会驱动资源模板按照当前分发规则立即分发。
- Lazy:策略变更暂时不生效,而是延迟到资源模板变更时生效。换句话说,资源模板不会按照当前分发规则重新分发,直到资源模板本身发生更新。
立即激活(默认)
使用默认的空值,策略变更会立即应用到所有资源模板:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
这会立即将策略变更应用到所有匹配的资源。
延迟激活
使用 Lazy 偏好设置,策略变更会延迟到资源模板更新时才生效:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
activationPreference: Lazy
placement:
clusterAffinity:
clusterNames:
- member1
这对于一个策略管理大量资源模板的场景很有帮助。通过使用此功能,策略变更只会在每个资源模板单独更新时才生效,允许分阶段推出而不会同时影响所有资源。
ActivationPreference 功能是实验特性。
此功能专门设计用于单个 PropagationPolicy 管理所有资源模板的场景。使用这种方式会导致配置的策略行为与实际行为不一致,可能导致意外的分发结果。
我们强烈建议在生产环境中避免使用此功能。如果必须使用,请确保:
- 在非生产环境中进行了充分的测试
- 完全理解了滚动策略
- 对分发行为保持密切监控
- 有应对问题的回滚计划
如果遇到任何问题或需要进一步指导,请联系 Karmada 团队寻求支持。
Suspension(暂停)
.spec.suspension 字段允许临时停止向所有集群或特定集群的分发。
暂停所有集群
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinity:
clusterNames:
- member1
- member2
suspension:
dispatching: true
deployment 的更新将不会同步到任何集群。
暂停特定集群
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinity:
clusterNames:
- member1
- member2
suspension:
dispatchingOnClusters:
clusterNames:
- member2
更新将同步到 member1 但不会同步到 member2。
恢复分发
删除 suspension 字段以恢复分发:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
placement:
clusterAffinity:
clusterNames:
- member1
- member2
删除 suspension 会恢复对两个集群的同步。
PreserveResourcesOnDeletion(删除时保留资源)
.spec.preserveResourcesOnDeletion 字段控制当资源模板被删除时是否应在成员集群上保留资源。
- true:删除�后资源保留在集群上
- false(默认):资源与模板一起删除
这对于工作负载迁移场景很有用,您希望在回滚之前保留运行的实例。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
preserveResourcesOnDeletion: true
placement:
clusterAffinity:
clusterNames:
- member1
这使分发的 Deployment 即使源被删除也在 member1 上保持运行。
SchedulePriority(调度优先级)
.spec.schedulePriority 字段启用基于优先级的调度(目前处于 alpha 阶段,由 PriorityBasedScheduling 功能门控制)。
这允许指定用于调度决策的 PriorityClass:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: high-priority-workload
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
schedulePriority:
priorityClassSource: KubePriorityClass
priorityClassName: high-priority
placement:
clusterAffinity:
clusterNames:
- member1
这使调度在做出放置决策时遵守 Kubernetes PriorityClass high-priority。
SchedulePriority 功能是 alpha 版本,可能在未来版本中更改。抢占功能尚不可用。