调度多组件工作负载
概述
许多现代分布式应用程序由具有异构资源需求的多个组件组成。例如,Flink 集群包含 JobManager 和 TaskManager 组件,而 Ray 集群则包含 Head 和 Worker 节点。每个组件通常具有不同的副本数和资源规格。
从 Karmada v1.16 开始,多 Pod 模板调度功能为这些复杂工作负载提供��了精确的资源感知调度能力。这确保了 Karmada 能够正确理解多组件应用程序的总资源需求,并在成员集群之间做出明智的调度决策。
为什么需要多组件调度?
在 v1.16 之前,Karmada 调度器假设工作负载中的所有副本都是相同的,使用单一的 Pod 模板来表示资源需求。这种假设对于 Deployment 等简单应用程序效果良好,但对于多组件工作负载则会导致不准确的情况。
考虑一个具有两个组件的 FlinkDeployment:
- JobManager:1 个副本,需要 1 CPU 和 2Gi 内存
- TaskManager:3 个副本,每个需要 2 CPU 和 4Gi 内存
使用传统调度,调度器只能表示一个组件的需求,导致:
- 低估:将 JobManager 配置应用于所有副本 → 仅计算 4 个 CPU 总量(实际需要 7 个)→ 存在调度到资源不足集群的风险(Pod Pending)。
- 高估:将 TaskManager 配置应用于所有副本 → 估计 8 个 CPU 总量(实际需要 7 个)→ 浪费资源并限制集群选择。
- 配额计算不准确:FederatedResourceQuota 显示错误的使用情况。
使用多组件调度,调度器能够准确理解:
- 所需的总资源:(1 × 1 CPU + 1 × 2Gi) + (3 × 2 CPU + 3 × 4Gi) = 7 CPU 和 14Gi 内存
- 每个组件的具体需求
- 集群是否能够容纳所有组件
支持的工作负载类型
多组件调度功能专为具有多个异构 Pod 模板的 CRD 设计。常见用例包括:
| 类别 | 示例 |
|---|---|
| 流处理 | Flink、Kafka Streams、Apache Storm |
| AI/ML 框架 | Ray、TensorFlow、PyTorch、MXNet |
| 机器学习训练 | 参数服务器、分布式训练作业 |
| 批处理 | Spark、Volcano、Hadoop |
| 数据处理 | XGBoost、PaddlePaddle、分布式数据库 |
| 分布式系统 | Elasticsearch、Redis Cluster、数据库集群 |
Karmada 为流行的 CRD 提供了内置的解释器支持。您可以在资源解释器文档中找到具有内置解释器支持的 CRD 列表。对于新的 CRD 类型或自定义工作负载,您可以实现自定义解释器(参见自定义资源解释器)或联系 Karmada 社区获取支持。
功能成熟度和要求
多组件调度功能目前处于 Alpha 阶段,从 Karmada v1.16 开始提供。作为 Alpha 功能,它在未来版本中可能会发生变化,但核心调度功能已完全可用,可用于评估和测试环境。
要使用多组件调度功能,您必须启用 MultiplePodTemplatesScheduling 特性门控。该特性门控必须在以下组件上启用:
karmada-controller-manager:负责解释多组件工作负载规格并在 ResourceBinding 对象中填充组件信息。karmada-scheduler:负责基于控制器提取的组件资源需求进行调度决策。karmada-webhook:负责验证从资源模板解析的组件信息。
工作原理
下图展示了多组件调度的过程,以 FlinkDeployment 为例。相同的工作流程也适用于其他多组件应用程序,如 RayCluster、TensorFlow 集群和其他分布式系统。
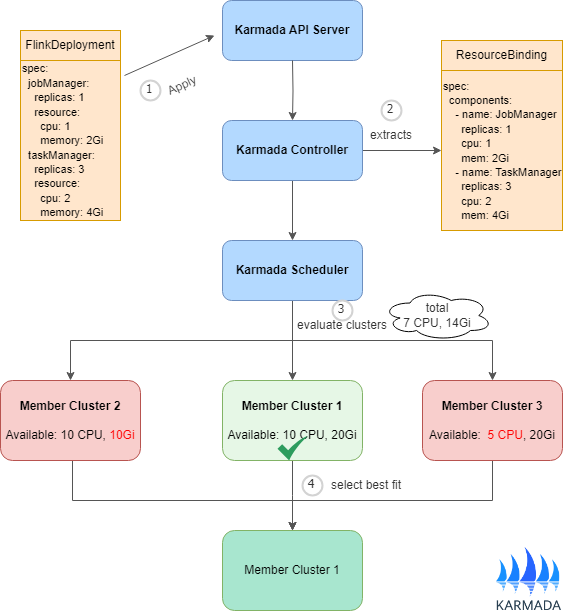
上图显示了调度工作流程:
-
多组件应用程序(例如 FlinkDeployment、RayCluster)被提交到 Karmada API Server。需要提供
PropagationPolicy或ClusterPropagationPolicy来指定工作负载应如何在成员集群之间分发。 -
Karmada 控制器利用资源解释器来解析每个组件的资源需求。这些需求存储在 ResourceBinding 对象的
spec.components字段中。 -
调度器基于每个组件逐个评估候选集群,而不是简单地按总资源求和。例如,它检查集群是否可以容纳 JobManager,然后检查同一集群是否也可以容纳所有 TaskManager。这种方法更好地考虑了集群节点之间的资源分布和碎片化。
-
调度器选择可以满足所有组件需求的集群。然后将所有组件作为单个单元调度到该集群。
限制和约束
目前,多组件调度功能具有以下限制:
- 工作负载的所有组件必须调度到同一个集群
- 尚不支持跨集群组件分发
多组件工作负载通常在组件之间存在紧密耦合(共享存储、网络连接、同步需求)。将组件分发到不同集群会在资源管理、故障处理和性能优化方面带来显著的复杂性。
我们认识到,将组件分发到不同集群是更好地利用多集群资源的自然演进。这种方法可以实现更灵活的资源分配和提高基础设施的利用率。但是,支持这一点需要:
- 用户定义明确的拆分规则和策略,以确保组件被适当放置
- 依赖关系和亲和性规范,以防止导致调度成功但无法运行的不兼容放置
我们欢迎有关跨集群组件分发的用户反馈和用例。如果您有特定的需求或场景,请随时联系我们。