Federated ResourceQuota
Background
With the widespread use of multi-clusters, the administrator may deploy services on multiple clusters and resource management of services under multiple clusters has become a new challenge.
A traditional approach is that the administrator manually deploys a namespace and ResourceQuota under each Kubernetes cluster, where Kubernetes will limit the resources according to the ResourceQuotas.
This approach is a bit inconvenient and not flexible enough.
In addition, this practice is now challenged by the differences in service scale, available resources and resource types of each cluster.
Resource administrators often need to manage and control the consumption of resources by each service in a global view.
Here's where the FederatedResourceQuota API comes in. The following is several typical usage scenarios of FederatedResourceQuota.
What FederatedResourceQuota can do
FederatedResourceQuota supports:
- Global quota management for applications that run on multiple clusters.
- Fine-grained management of quotas under the same namespace of different clusters.
- Ability to enumerate resource usage limits per namespace.
- Ability to monitor resource usage for tracked resources.
- Ability to reject resource usage exceeding hard quotas.
You can use FederatedResourceQuota to manage CPU, memory, storage and ephemeral-storage.
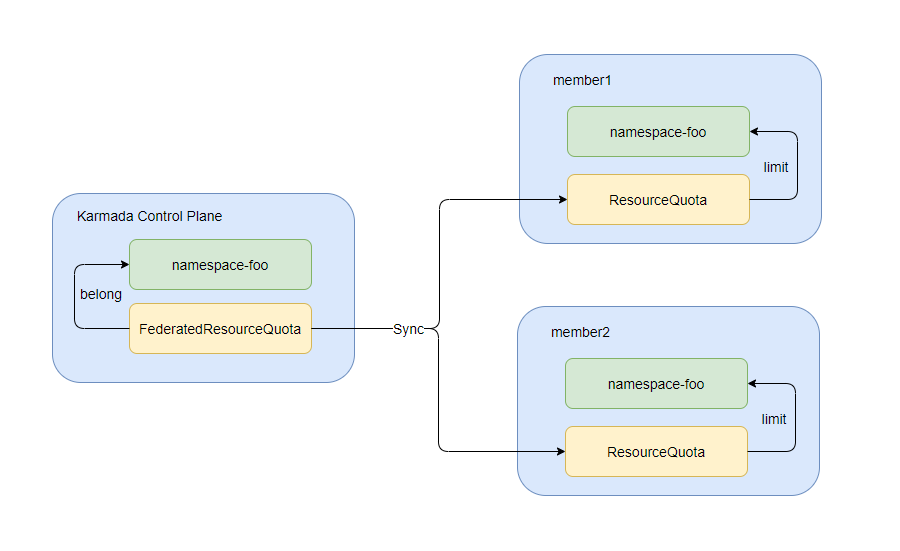
Deploy a simplest FederatedResourceQuota
Assume you, an administrator, want to deploy service A across multiple clusters in namespace test.
You can create a namespace called test on the Karmada control plane. Karmada will automatically create the corresponding namespace in the member clusters.
kubectl --kubeconfig ~/.kube/karmada.config --context karmada-apiserver create ns test
You want to create a CPU limit of 100 cores for service A. The available resources on clusters:
- member1: 20C
- member2: 50C
- member3: 100C
In this example, allocate 20C of member1, 50C of member2, and 30C of member3 to service A. Resources are reserved for more important services in member3.
You can deploy a FederatedResourceQuota as follows.
apiVersion: policy.karmada.io/v1alpha1
kind: FederatedResourceQuota
metadata:
name: test
namespace: test
spec:
overall:
cpu: 100
staticAssignments:
- clusterName: member1
hard:
cpu: 20
- clusterName: member2
hard:
cpu: 50
- clusterName: member3
hard:
cpu: 30
Verify the status of FederatedResourceQuota:
kubectl --kubeconfig ~/.kube/karmada.config --context karmada-apiserver get federatedresourcequotas/test -ntest -oyaml
The output is similar to:
spec:
overall:
cpu: 100
staticAssignments:
- clusterName: member1
hard:
cpu: 20
- clusterName: member2
hard:
cpu: 50
- clusterName: member3
hard:
cpu: 30
status:
aggregatedStatus:
- clusterName: member1
hard:
cpu: "20"
used:
cpu: "0"
- clusterName: member2
hard:
cpu: "50"
used:
cpu: "0"
- clusterName: member3
hard:
cpu: "30"
used:
cpu: "0"
overall:
cpu: "100"
overallUsed:
cpu: "0"
For quick test, you can deploy a simple application which consumes 1C CPU to member1.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: test
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: 1
Verify the status of FederatedResourceQuota and you will find that FederatedResourceQuota can monitor resource usage correctly for tracked resources.
kubectl --kubeconfig ~/.kube/karmada.config --context karmada-apiserver get federatedresourcequotas/test -ntest -oyaml
spec:
overall:
cpu: 100
staticAssignments:
- clusterName: member1
hard:
cpu: 20
- clusterName: member2
hard:
cpu: 50
- clusterName: member3
hard:
cpu: 30
status:
aggregatedStatus:
- clusterName: member1
hard:
cpu: "20"
used:
cpu: "1"
- clusterName: member2
hard:
cpu: "50"
used:
cpu: "0"
- clusterName: member3
hard:
cpu: "30"
used:
cpu: "0"
overall:
cpu: "100"
overallUsed:
cpu: "1"
FederatedResourceQuota is still a work in progress. We are in the progress of gathering use cases. If you are interested in this feature, please feel free to start an enhancement issue to let us know.