联邦资源配额
背景
随着多集群的广泛使用,管理员可能会在多个集群上部署服务,而多个集群下服务的资源管理已成为新的挑战。
传统方法是管理员在每个 Kubernetes 集群下手动部署一个命名空间和 ResourceQuota,Kubernetes 将根据 ResourceQuotas 限制此命名空间下的资源。
这种方法有点不方便,也不够灵活。
此外,多集群场景下此类方法也面临着每个集群�的服务规模、可用资源和资源类型差异的挑战。
资源管理员通常需要从全局视角管理和控制每个服务的资源消耗。这就是 FederatedResourceQuota API 的用武之地。以下是FederatedResourceQuota的几个典型使用场景。
FederatedResourceQuota 能做什么
FederatedResourceQuota 支持:
- 资源配额管理
- 设置和跟踪跨集群部署的联邦应用程序的总体配额使用情况。还支持对不同集群的相同命名空间下的配额进行细粒度管理,包括:
- 枚举每个命名空间的资源使用限制的能力。
- 监控跟踪资源的资源使用情况的能力。
- 拒绝超过硬配额的资源使用的能力。
- 设置和跟踪跨集群部署的联邦应用程序的总体配额使用情况。还支持对不同集群的相同命名空间下的配额进行细粒度管理,包括:
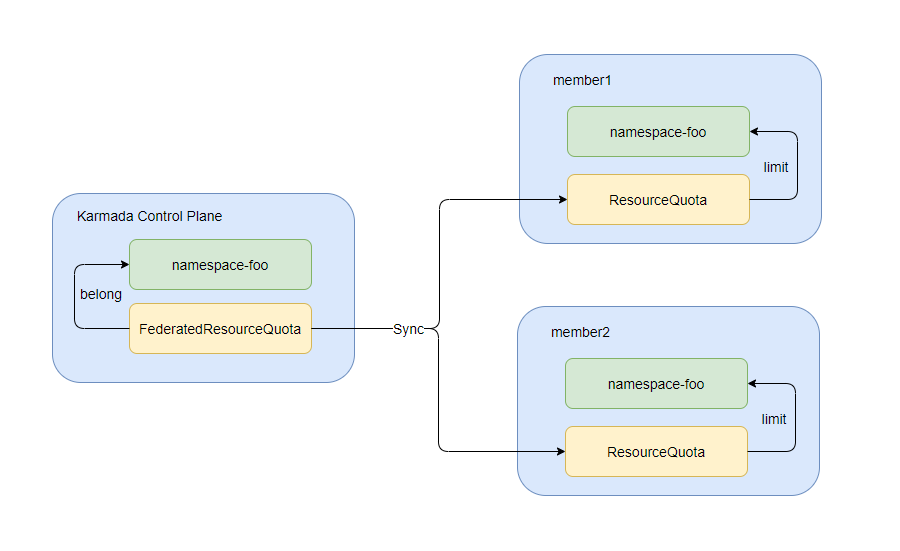
- Karmada 控制面级别的配额管理
- 支持在联邦级别而不仅仅是每个集群执行命名空间资源限制。
- 集中配额检查:
- 针对Karmada控制平面的资源创建和更新
- 通过拒绝会超过命名空间总配额的调度请求来防止过度调度。
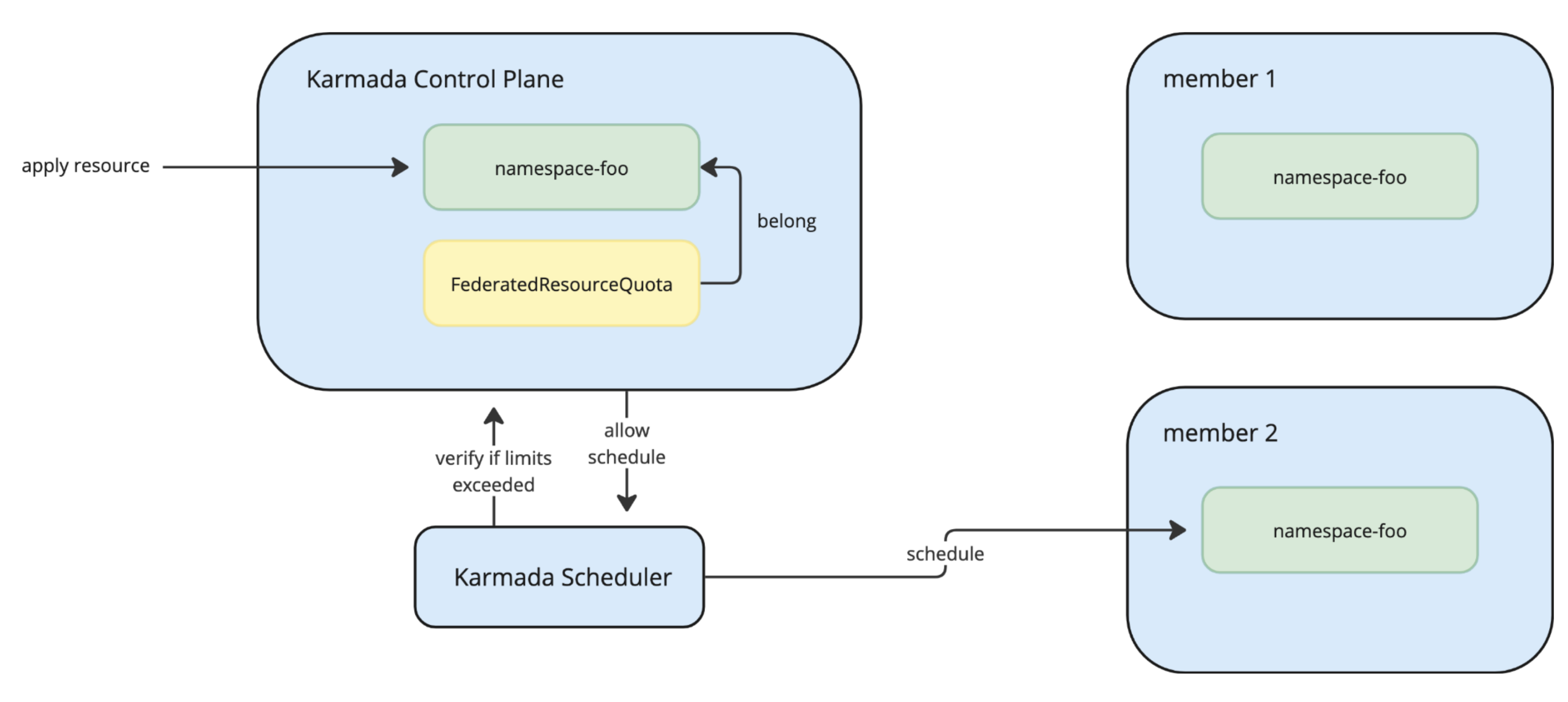
您可以使用 FederatedResourceQuota 来管理CPU、内存、存储和临时存�储。
部署一个简单的 FederatedResourceQuota
假设您作为管理员,想在命名空间 test 中跨多个集群部署服务 A。
您可以在 Karmada 控制平面上创建一个名为 test 的命名空间。Karmada 将自动在成员集群中创建相应的命名空间。
kubectl --kubeconfig ~/.kube/karmada.config --context karmada-apiserver create ns test
您想为服务A 创建 100 核的 CPU 限制。 集群上的可用资源:
- member1:20C
- member2:50C
- member3:100C
在此示例中,将 member1 的 20C、member2 的 50C 和 member3 的 30C 分配给服务A。为 member3 中的更重要服务保留资源。
您可以按如下方式部署 FederatedResourceQuota。
apiVersion: policy.karmada.io/v1alpha1
kind: FederatedResourceQuota
metadata:
name: test
namespace: test
spec:
overall:
cpu: 100
staticAssignments:
- clusterName: member1
hard:
cpu: 20
- clusterName: member2
hard:
cpu: 50
- clusterName: member3
hard:
cpu: 30
验证 FederatedResourceQuota 的状态:
kubectl --kubeconfig ~/.kube/karmada.config --context karmada-apiserver get federatedresourcequotas/test -ntest -oyaml
输出类似于:
spec:
overall:
cpu: 100
staticAssignments:
- clusterName: member1
hard:
cpu: 20
- clusterName: member2
hard:
cpu: 50
- clusterName: member3
hard:
cpu: 30
status:
aggregatedStatus:
- clusterName: member1
hard:
cpu: "20"
used:
cpu: "0"
- clusterName: member2
hard:
cpu: "50"
used:
cpu: "0"
- clusterName: member3
hard:
cpu: "30"
used:
cpu: "0"
overall:
cpu: "100"
overallUsed:
cpu: "0"
为了快速测试,您可以部署一个消耗 1C CPU 的简单应用程序到 member1。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: test
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: 1
验证 FederatedResourceQuota 的状态,您会发现 FederatedResourceQuota 可以正确监控跟踪资源的资源使用情况。
kubectl --kubeconfig ~/.kube/karmada.config --context karmada-apiserver get federatedresourcequotas/test -ntest -oyaml
spec:
overall:
cpu: 100
staticAssignments:
- clusterName: member1
hard:
cpu: 20
- clusterName: member2
hard:
cpu: 50
- clusterName: member3
hard:
cpu: 30
status:
aggregatedStatus:
- clusterName: member1
hard:
cpu: "20"
used:
cpu: "1"
- clusterName: member2
hard:
cpu: "50"
used:
cpu: "0"
- clusterName: member3
hard:
cpu: "30"
used:
cpu: "0"
overall:
cpu: "100"
overallUsed:
cpu: "1"
使用控制面级别的配额管理
控制面级别的配额管理是一项新功能。此功能需要启用FederatedQuotaEnforcement特性门控。目前处于Alpha阶段,默认情况下是关闭的。
FederatedResourceQuota 的基本功能允许用户使用 staticAssignment 控制跨多个集群的总体资源限制的资源配额。但是,您也可以使用 FederatedResourceQuota 直接对 Karmada 控制平面施加和执行资源限制。
这在以下情况下尤其有用:
- 您需要从统一的位置跟踪资源消耗和限制
- 您希望通过限制配额资源来防止不必要地调度资源到成员集群
使用前面的示例,假设您想将总体 CPU ��限制设置为 100。您需要做的就是定义 Overall 限制:
apiVersion: policy.karmada.io/v1alpha1
kind: FederatedResourceQuota
metadata:
name: test
namespace: test
spec:
overall:
cpu: 100
一旦应用,Karmada 将开始监控和执行 test 命名空间的 CPU 资源限制。假设您应用了一个需要 20 个 CPU 的新 Deployment。联邦资源配额的状态将更新为如下所示:
spec:
overall:
cpu: 100
status:
overall:
cpu: "100"
overallUsed:
cpu: "20"
如果您应用的资源超过 100 个CPU的限制,该资源将不会被调度到您的成员集群。
联邦资源配额仍在开发中。我们正在收集用例。如果您对此功能感兴趣,请随时发起 enhancement issue 让我们知道。