Karmada 是开放的多云多集群容器编排引擎,旨在帮助用户在多云环境下部署和运维业务应用。凭借兼容 Kubernetes 原生 API 的能力,Karmada 可以 平滑迁移单集群工作负载,并且仍可保持与 Kubernetes 周边生态工具链协同。
Karmada v1.14 版本现已发布,本版本包含下列新增特性:
- 新增联邦资源配额管理能力,用于多租户场景下资源治理
- 新增定制化污点管理能力,消除隐式集群故障迁移
- Karmada Operator 功能持续演进
- Karmada 控制器性能显著提升
新特性概览
联邦资源配额管理
在多租户的云基础设施中,配额管理是确保资源公平分配和防止超额使用的关键。尤其在多云多集群环境下,分散的配额系统往往导致资源监控困难和管理割 裂,因此实现跨集群的联邦配额管理成为提升资源治理效率的核心要素。
此前,Karmada 通过 FederatedResourceQuota 将全局配额分配至成员集群,由各集群本地实施配额管控。本次版本升级增强了联邦配额管理能力,新 增控制平面全局配额检查机制,支持直接在控制平面进行全局资源配额校验。
该功能特别适用于以下场景:
- 您需要从统一位置跟踪资源消耗和限制,而无需关注集群级别的分配情况。
- 您希望通过验证配额限制来避免超额的任务提交。
注意:该特性目前处于 Alpha 阶段,需要启用 FederatedQuotaEnforcement Feature Gate 才能使用。
假设您想设置总体 CPU 限制为 100,您可以按照如下配置进行定义:
apiVersion: policy.karmada.io/v1alpha1
kind: FederatedResourceQuota
metadata:
name: team-foo
namespace: team-foo
spec:
overall:
cpu: 100
一旦应用,Karmada 将开始监控和执行 test 命名空间的 CPU 资源限制。假设您应用了一个需要 20 个 CPU 的新 Deployment。联邦资源配额的状态 将更新为如下所示:
spec:
overall:
cpu: 100
status:
overall:
cpu: 100
overallUsed:
cpu: 20
如果您应用的资源超过 100 个CPU的限制,该资源将不会被调度到您的成员集群。
有关此功能的详细用法,可以参考特性使用文档:Federated ResourceQuota。
定制化污点管理
在 v1.14 之前的版本中,当用户启用故障转移功能时,系统在检测到健康状态异常后会自动向集群添加一个 NoExecute effect 污点,从而触发目标集 群上所有资源的迁移。
在这个版本中,我们对系统中潜在的迁移触发因素进行了全面审查。所有隐含的集群故障转移行为已被消除,并且引入了针对集群故障机制的明确约束条件。 这使得因集群故障而引发的资源迁移能够得到统一管理,进一步增强了系统的稳定性和可预测性。
集群故障条件是通过评估出现故障的集群对象的状态条件来确定的,以便应用污点,这一过程可以称为“Taint Cluster By Conditions”。此版本引入了 一个新的 API - ClusterTaintPolicy,它允许用户自定义规则,以便在预定义的集群状态条件得到满足时,为目标集群添加特定的污点。
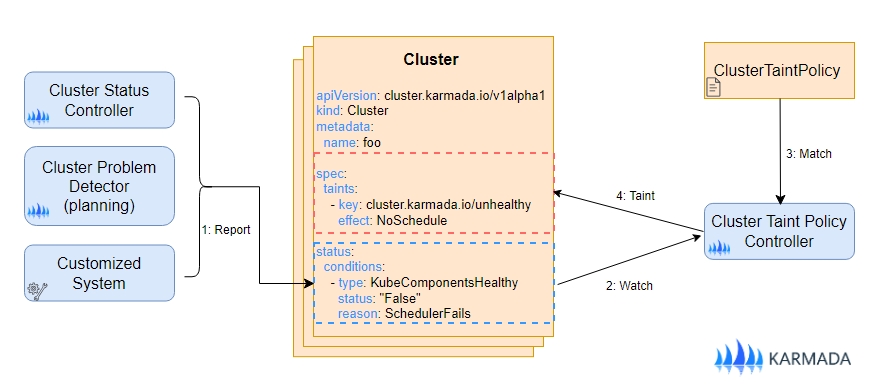
对于更复杂的集群故障判断场景,用户可以直接实现一个自定义的“集群污点控制器”,以控制如何向集群对象添加或移除污点。
ClusterTaintPolicy 是一种 Cluster scope 资源,下面我们给一个简单的例子来说明它的用法:
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterTaintPolicy
metadata:
name: detect-cluster-notready
spec:
targetClusters:
clusterNames:
- member1
- member2
addOnConditions:
- conditionType: Ready
operator: NotIn
statusValues:
- "True"
- conditionType: NetworkAvailable
operator: NotIn
statusValues:
- "True"
removeOnConditions:
- conditionType: Ready
operator: In
statusValues:
- "True"
- conditionType: NetworkAvailable
operator: In
statusValues:
- "True"
taints:
- key: not-ready
effect: NoSchedule
- key: not-ready
effect: NoExecute
上面的例子描述了一个针对 member1 和 member2 集群的 ClusterTaintPolicy 资源,当集群的状态条件同时满足 Type 为 Ready 和 NetworkAvailable
的 condition value 不等于 True 时,会为目标集群添加污点 {not-ready:NoSchedule} 与 {not-ready:NoExecute};当集群的状态条件同
时满足 Type 为 Ready 和 NetworkAvailable 的 condition value 等于 True 时,会移除目标集群上的污点 {not-ready:NoSchedule}
和 {not-ready:NoExecute}。
有关此功能的详细用法,可以参考特性使用文档:集群污点管理。
Karmada Operator 功能持续演进
本版本持续增强 Karmada Operator,新增以下功能:
- 支持配置 Leaf 证书有效期。
- 支持 Karmada 控制平面暂停调谐。
- 支持为
karmada-webhook组件配置 feature gates。 - 支持为
karmada-apiserver组件执行loadBalancerClass以选择特定的负载均衡实现。 - 引入
karmada_build_info指标来展示构建信息,以及一组运行时指标。
这些改进使得 karmada-operator 更加灵活且可定制,提高了整个 Karmada 系统的可靠性和稳定性。
Karmada 控制器性能显著提升
自 1.13 版本发布以来,Karmada adopters 自发组织起来对 Karmada 性能进行优化。如今,一个稳定且持续运作的性能优化团队 SIG-Scalability 已经组建,致力于提升 Karmada 的性能与稳定性。感谢所有参与者付出的努力。如果大家有兴趣,随时欢迎大家加入。
在本次版本中,Karmada 实现了显著的性能提升,尤其是在 karmada-controller-manager 组件中。为验证这些改进,实施了以下测试设置:
测试设置包括 5000 个 Deployment,每个 Deployment 都与一个相应的 PropagationPolicy 配对,该策略将其调度到两个成员集群。每个 Deployment
还依赖一个唯一的 ConfigMap,它会与 Deployment 一起分发到相同的集群。这些资源是在 karmada-controller-manager 组件离线时创建的,这
意味着在测试期间 Karmada 首次对它们进行同步。测试结果如下:
- 冷启动时间(清空工作队列)从约 7 分钟缩短至约 4 分钟,提升了 45%。
- 资源检测器:平均处理时间的最大值从 391 毫秒降至 180 毫秒(提升了 54%)。
- 依赖分发器:平均处理时间的最大值从 378 毫秒降至 216 毫秒(提升了 43%)。
- 执行控制器:平均处理时间的最大值从 505 毫秒降至 248 毫秒(提升了 50%)。
除了更快的处理速度,资源消耗也显著降低:
- CPU使用率从 4 - 7.5 核降至 1.8 - 2.4 核(降幅 40% - 65%)。
- 内存峰值使用量从 1.9 GB 降至 1.47 GB(降幅 22%)。
这些数据证明,在 1.14 版本中,Karmada 控制器的性能得到了极大提升。未来,我们将继续对控制器和调度器进行系统性的性能优化。
相关的详细测试报告,请参考 [Performance] Overview of performance improvements for v1.14。
致谢贡献者
Karmada v1.14 版本包含了来自 30 位贡献者的 271 次代码提交,在此对各位贡献者表示由衷的感谢:
| ^-^ | ^-^ | ^-^ |
|---|---|---|
| @Arhell | @baiyutang | @chaosi-zju |
| @CharlesQQ | @dongjiang1989 | @everpeace |
| @husnialhamdani | @ikaven1024 | @jabellard |
| @liangyuanpeng | @likakuli | @LivingCcj |
| @liwang0513 | @MdSayemkhan | @mohamedawnallah |
| @mojojoji | @mszacillo | @my-git9 |
| @Pratham-B-Parlecha | @RainbowMango | @rajsinghtech |
| @seanlaii | @tangzhongren | @tiansuo114 |
| @vie-serendipity | @warjiang | @whosefriendA |
| @XiShanYongYe-Chang | @zach593 | @zhzhuang-zju |