Cluster Failover
In the multi-cluster scenario, user workloads may be deployed in multiple clusters to improve service high availability. In Karmada, when a cluster fails or the user does not want to continue running workloads on a cluster, users can manage cluster taints to evict workloads from the cluster or prevent new workloads from being scheduled to the target cluster.
The evicted workloads will be scheduled to other best-fit clusters, thus achieving cluster failover and ensuring the availability and continuity of user services.
Why Cluster Failover Is Required
The following describes some scenarios of multi-cluster failover:
- The administrator deploys an offline application on the Karmada control plane and distributes the Pod instances to multiple clusters. When a cluster becomes faulty, the administrator wants Karmada to migrate Pod instances in the faulty cluster to other clusters that meet proper conditions.
- A common user deploys an online application on a cluster through the Karmada control plane. The application includes database instances, server instances, and configuration files. The application is exposed through the ELB on the control plane. In this case, a cluster is faulty. The customer wants to migrate the entire application to another suitable cluster. During the application migration, ensure that the service is uninterrupted.
- After an administrator upgrades a cluster, the container network and storage devices used as infrastructure in the cluster are changed. The administrator wants to migrate applications in the cluster to another proper cluster before the cluster upgrade. During the migration, services must be continuously provided.
- ......
How to Perform Cluster Failover
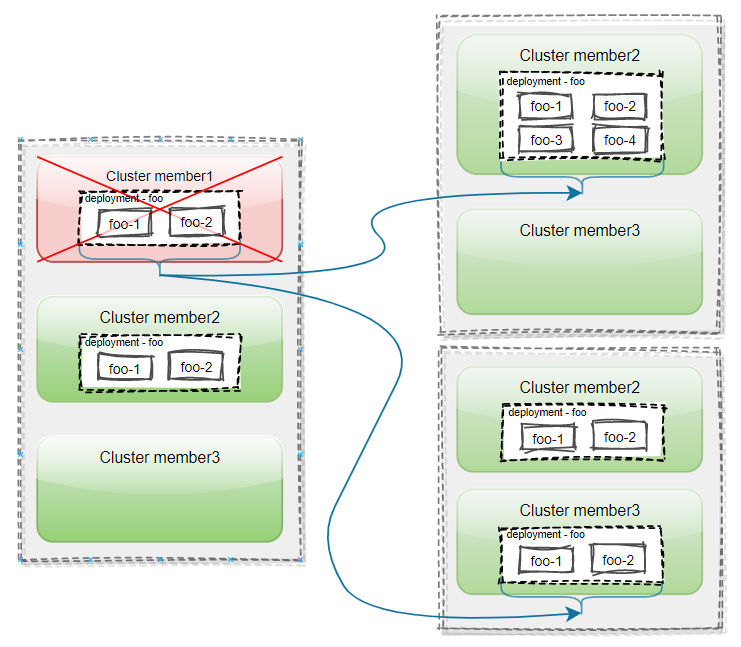
The user has joined three clusters in Karmada: member1, member2, and member3. A Deployment named foo, which has 4 replicas, is deployed on the karmada control-plane. The deployment is distributed to cluster member1 and member2 by using PropagationPolicy.
When cluster member1 fails, pod instances on the cluster are evicted and migrated to cluster member2 or the new cluster member3. This different migration behavior can be controlled by the replica scheduling policy ReplicaSchedulingStrategy of PropagationPolicy/ClusterPropagationPolicy.
How Do I Enable the Feature?
The cluster failover feature is controlled by the Failover feature gate. Failover feature gate is currently in the Beta stage and is turned off by default, which should be explicitly enabled to avoid unexpected incidents. You can enable it in the karmada-controller-manager:
--feature-gates=Failover=true
Configure Cluster Failover
When a cluster is tainted with NoExecute, it will trigger the migration of workloads from that cluster. For detailed migration mechanisms, please refer to Failover Analysis. In addition, users can configure the behavior of cluster failover through the .spec.failover.cluster field of the PropagationPolicy API, enabling fine-grained control over application-level cluster failover behavior.
ClusterFailoverBehavior provides the following configurable fields:
- PurgeMode
- StatePreservation
Configure PurgeMode
PurgeMode represents how to deal with the legacy applications on the cluster from which the application is migrated. Currently, the supported values are Directly and Gracefully, with the default being Gracefully. The explanations for each type are as follows:
Directlyrepresents that Karmada will directly evict the legacy application. This is useful in scenarios where an application cannot tolerate two instances running simultaneously. For example, the Flink application supports exactly-once state consistency, which means it requires that no two instances of the application are running at the same time. During a failover, it is crucial to ensure that the old application is removed before creating a new one to avoid duplicate processing and maintaining state consistency.Gracefullyrepresents that Karmada will wait for the application to become healthy on the new cluster or after a timeout is reached before evicting the application.
PropagationPolicy can be configured as follows:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
failover:
cluster:
purgeMode: Directly
#...
Application State Preservation
Starting from version v1.15, the cluster failover feature has added support for stateful applications, providing users with a general way to define application state preservation in the context of cluster failover.
StatePreservation Introduction
Karmada currently supports propagating various types of resources, including Kubernetes objects and CRDs (Custom Resource Definitions), which also covers stateful workloads. This enables distributed applications to achieve multi-cluster resilience and elastic scaling. Stateless workloads have the advantage of higher fault tolerance, as the loss of a workload does not affect the correctness of the application and does not require data recovery. In contrast, stateful workloads (such as Flink) rely on checkpoints or saved state to recover after a failure. If this state is lost, the job may not be able to resume from where it left off.
Defining StatePreservation
StatePreservation is a field under .spec.failover.cluster. It defines the policy for preserving and restoring state data during failover events for stateful applications. When an application fails over from one cluster to another, this policy enables the extraction of critical data from the original resource configuration.
It contains a list of StatePreservationRule configurations. Each rule specifies a JSONPath expression targeting specific pieces of state data to be preserved during failover events. An AliasLabelName is associated with each rule, serving as a label key when the preserved data is passed to the new cluster.
Example of StatePreservation Configuration
Taking Flink as an example, jobID is a unique identifier used to distinguish and manage different Flink jobs. When a cluster failure occurs, the Flink application can use the jobID to obtain the checkpoint data storage, restore the job state before the cluster failure, and then continue execution from the failure point in the new cluster. The configuration and steps are as follows:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: flink-propagation
spec:
resourceSelectors:
- apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
name: flink-app
failover:
cluster:
purgeMode: Directly
statePreservation:
rules:
- aliasLabelName: application.karmada.io/cluster-failover-jobid
jsonPath: "{ .jobStatus.jobID }"
placement:
clusterAffinity:
clusterNames:
- member1
- member2
spreadConstraints:
- maxGroups: 1
minGroups: 1
spreadByField: cluster
StatePreservation Field Description
- rules: A list containing multiple
StatePreservationRuleconfigurations- aliasLabelName: The name used as the label key when the preserved data is passed to the new cluster
- jsonPath: The JSONPath template used to identify the state data to be preserved from the original resource configuration
StatePreservation Workflow
- Before migration: The Karmada controller retrieves the job ID from the status of FlinkDeployment according to the
jsonPathconfigured by the user. - During migration: The Karmada controller injects the extracted job ID as a label into the Flink application configuration, for example,
application.karmada.io/cluster-failover-jobid: <jobID>. - Target cluster processing: Kyverno running on the member cluster intercepts the FlinkDeployment creation request, obtains the checkpoint data storage path for the job based on the
jobID, such as/<shared-path>/<job-namespace>/<jobID>/checkpoints/xxx, and then configuresinitialSavepointPathto indicate that it will start from the savepoint. - Resuming execution: FlinkDeployment starts based on the checkpoint data under
initialSavepointPath, thus inheriting the final state saved before migration.
Usage Limitations and Notes
This feature requires enabling the StatefulFailoverInjection feature gate. StatefulFailoverInjection is currently in the Alpha stage and is disabled by default.
There are currently some limitations when using this feature. Please pay attention to the following:
- Only the scenario where the application is deployed in one cluster and migrated to another cluster is considered
- If consecutive failovers occur, for example, the application is migrated from clusterA to clusterB and then to clusterC, the PreservedLabelState before the last failover is used for injection. If the PreservedLabelState is empty, the injection is skipped
- The injection operation is performed only when PurgeMode is set to Directly
JSONPath Syntax Description
JSONPath expressions follow the Kubernetes specification: https://kubernetes.io/docs/reference/kubectl/jsonpath/ .
Note: JSONPath expressions by default start searching from the "status" field of the API resource object. For example, to extract "availableReplicas" from a Deployment, the JSONPath expression should be {.availableReplicas} instead of {.status.availableReplicas}.
Configuring Eviction Rate Limiting
In scenarios involving large-scale failures across multiple clusters, simultaneously evicting a large number of workloads can put immense pressure on the Karmada control plane and the remaining healthy clusters. To improve the stability and controllability of the failover process, Karmada introduces a rate limiting mechanism, allowing the eviction rate to be adjusted as needed via command-line parameters.
You can fine-tune the eviction behavior by configuring the following command-line parameters on the karmada-controller-manager component:
--resource-eviction-rate: Number of evictions per second. Default: 0.5. When the value is 0, the acceleration speed will be set to run at a rate of 30 minutes per cycle.
Examples:
- If 12 workloads must be evicted and
--resource-eviction-rate=0.5, Karmada evicts roughly one workload every 2 seconds and completes in about 24 seconds. - If set to
--resource-eviction-rate=2, about 2 resources will be evicted per second, completing in roughly 6 seconds.
Cluster failover is still in continuous iteration. We are in the progress of gathering use cases. If you are interested in this feature, please feel free to start an enhancement issue to let us know.